442: fix phrase search r=curquiza a=MarinPostma
Run the exact match search on 7 words windows instead of only two. This makes false positive very very unlikely, and impossible on phrase query that are less than seven words.
Co-authored-by: ad hoc <postma.marin@protonmail.com>
2136: Refactoring CI regarding ARM binary publish r=curquiza a=curquiza
Fixes https://github.com/meilisearch/meilisearch/issues/1909
- Remove CI file to publish aarch64 binary and put the logic into `publish-binary.yml`
- Remove the job to publish armv8 binary
- Fix download-latest script accordingly
- Adapt dowload-latest with the specific case of the MacOS m1
Co-authored-by: Clémentine Urquizar <clementine@meilisearch.com>
Co-authored-by: meili-bot <74670311+meili-bot@users.noreply.github.com>
445: allow null values in csv r=Kerollmops a=MarinPostma
This pr allows null values in csv:
- if the field is of type string, then an empty field is considered null (`,,`), anything other is turned into a string (i.e `, ,` is a single whitespace string)
- if the field is of type number, when the trimmed field is empty, we consider the value null (i.e `,,`, `, ,` are both null numbers) otherwise we try to parse the number.
Co-authored-by: ad hoc <postma.marin@protonmail.com>
417: Change chunk size to 4MiB to fit more the end user usage r=Kerollmops a=ManyTheFish
Reverts meilisearch/milli#379
We made several indexing tests using different sizes of datasets (5 datasets from 9MiB to 100MiB) on several typologies of VMs (`XS: 1GiB RAM, 1 VCPU`, `S: 2GiB RAM, 2 VCPU`, `M: 4GiB RAM, 3 VCPU`, `L: 8GiB RAM, 4 VCPU`).
The result of these tests shows that the `4MiB` chunk size seems to be the best size compared to other chunk sizes (`2Mib`, `4MiB`, `8Mib`, `16Mib`, `32Mib`, `64Mib`, `128Mib`).
below is the average time per chunk size:

<details>
<summary>Detailled data</summary>
<br>
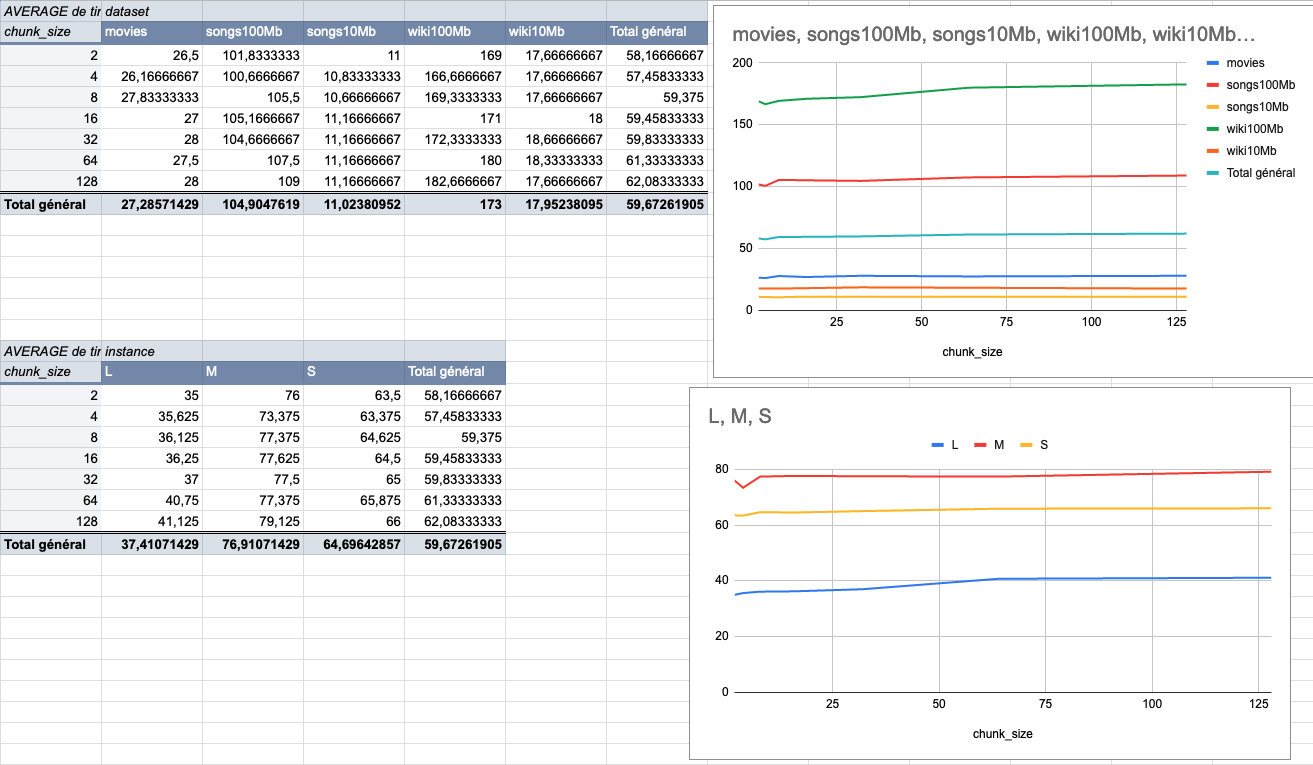
</br>
</details>
Co-authored-by: Many <many@meilisearch.com>
444: Fix the parsing of ndjson requests to index more than the first line r=Kerollmops a=Kerollmops
This PR correctly uses the `BufRead` trait to read every line of the content instead of just the first one. This bug was only affecting the http-ui test crate.
Co-authored-by: Kerollmops <clement@meilisearch.com>
2005: auto batching r=MarinPostma a=MarinPostma
This pr implements auto batching. The basic functioning of this is that all updates that can be batched together are batched together while the previous batch is being processed.
For now, the only updates that can be batched together are the document addition updates (both update and replace), for a single index.
The batching is disabled by default for multiple reasons:
- We need more experimentation with the scheduling techniques
- Right now, if one task fails in a batch, the whole batch fails. We need more permissive error handling when processing document indexation.
There are four CLI options, for now, to interact with how the batch is scheduled:
- `enable-autobatching`: enable the autobatching feature.
- `debounce-duration-sec`: When an update is received, wait that number of seconds before batching and performing the updates. Defaults to 0s.
- `max-batch-size`: the maximum number of tasks per batch, defaults to unlimited.
- `max-documents-per-batch`: the maximum number of documents in a batch, defaults to unlimited. The batch will always contain a least 1 task, no matter the number of documents in that task.
# Implementation
The current implementation is made of 3 major components:
## TaskStore
The `TaskStore` contains all the tasks. When a task is pushed, it is directly registered to the task store.
## Scheduler
The scheduler is in charge of making the batches. At its core, there is a `TaskQueue` and a job queue. `Job`s are always processed first. They are *volatile* tasks, that is, they don't have a TaskId and are not persisted to disk. Snapshots and dumps are examples of Jobs.
If no `Job` is available for processing, then the scheduler attempts to make a `Task` batch from the `TaskQueue`. The first step is to gather new tasks from the `TaskStore` to populate the `TaskQueue`. When this is done, we can prepare our batch. The `TaskQueue` is itself a `BinaryHeap` of `Tasklist`. Each `index_uid` is associated with a `TaskList` that contains all the updates associated with that index uid. Each `TaskList` in the `TaskQueue` is ordered by the id of its first task.
When preparing a batch, the `TaskList` at the top of the `TaskQueue` is popped, and the tasks are popped from the list to make the next batch. If there are remaining tasks in the list, the list is inserted back in the `TaskQueue`.
## UpdateLoop
The `UpdateLoop` role is to perform batch sequentially. Each time updates are pushed to the update store, the scheduler is notified, and will in turn notify the update loop that work can be performed. When notified, the update loop waits some time to wait for more incoming update and then asks the scheduler for the next batch to perform and perform it. When it is done, the status of the task is put back into the store, and the next batch is processed.
Co-authored-by: mpostma <postma.marin@protonmail.com>
2120: Bring `stable` into `main` r=curquiza a=curquiza
I forgot to do it, tell me `@Kerollmops` or `@irevoire` if it's useful or not. I would say yes, otherwise I will have conflict when I will try to bring `main` into `stable` for the next release. Maybe I'm wrong
Co-authored-by: Irevoire <tamo@meilisearch.com>
Co-authored-by: mpostma <postma.marin@protonmail.com>
Co-authored-by: Tamo <tamo@meilisearch.com>
Co-authored-by: bors[bot] <26634292+bors[bot]@users.noreply.github.com>
Co-authored-by: Clémentine Urquizar - curqui <clementine@meilisearch.com>
431: Fix and improve word prefix pair proximity r=ManyTheFish a=Kerollmops
This PR first fixes the algorithm we used to select and compute the word prefix pair proximity database. The previous version was skipping nearly all of the prefixes. The issue is that this fix made this method to take more time and we were trying to reduce the time spent in it.
With `@ManyTheFish` we found out that we could skip some of the work we were doing by:
- discarding the prefixes that were shorter than a specific threshold (default: 2).
- discarding the word prefix pairs with proximity bigger than a specific threshold (default: 4).
- remove the unused threshold that was specifying a minimum amount of word docids to merge.
We will take more time to do some more optimization, like stop clearing and recomputing from scratch the database, we will compute the subsets of keys to create, keep and merge. This change is a little bit more complex than what this PR does.
I keep this PR as a draft as I want to further test the real gain if it is enough or not if it is valid or not. I advise reviewers to review commit by commit to see the changes bit by bit, reviewing the whole PR can be hard.
Co-authored-by: Clément Renault <clement@meilisearch.com>
{kind=link}
{kind=link}