mirror of
https://github.com/meilisearch/meilisearch.git
synced 2025-03-03 04:14:15 +08:00
Merge #417
417: Change chunk size to 4MiB to fit more the end user usage r=Kerollmops a=ManyTheFish Reverts meilisearch/milli#379 We made several indexing tests using different sizes of datasets (5 datasets from 9MiB to 100MiB) on several typologies of VMs (`XS: 1GiB RAM, 1 VCPU`, `S: 2GiB RAM, 2 VCPU`, `M: 4GiB RAM, 3 VCPU`, `L: 8GiB RAM, 4 VCPU`). The result of these tests shows that the `4MiB` chunk size seems to be the best size compared to other chunk sizes (`2Mib`, `4MiB`, `8Mib`, `16Mib`, `32Mib`, `64Mib`, `128Mib`). below is the average time per chunk size:  <details> <summary>Detailled data</summary> <br> 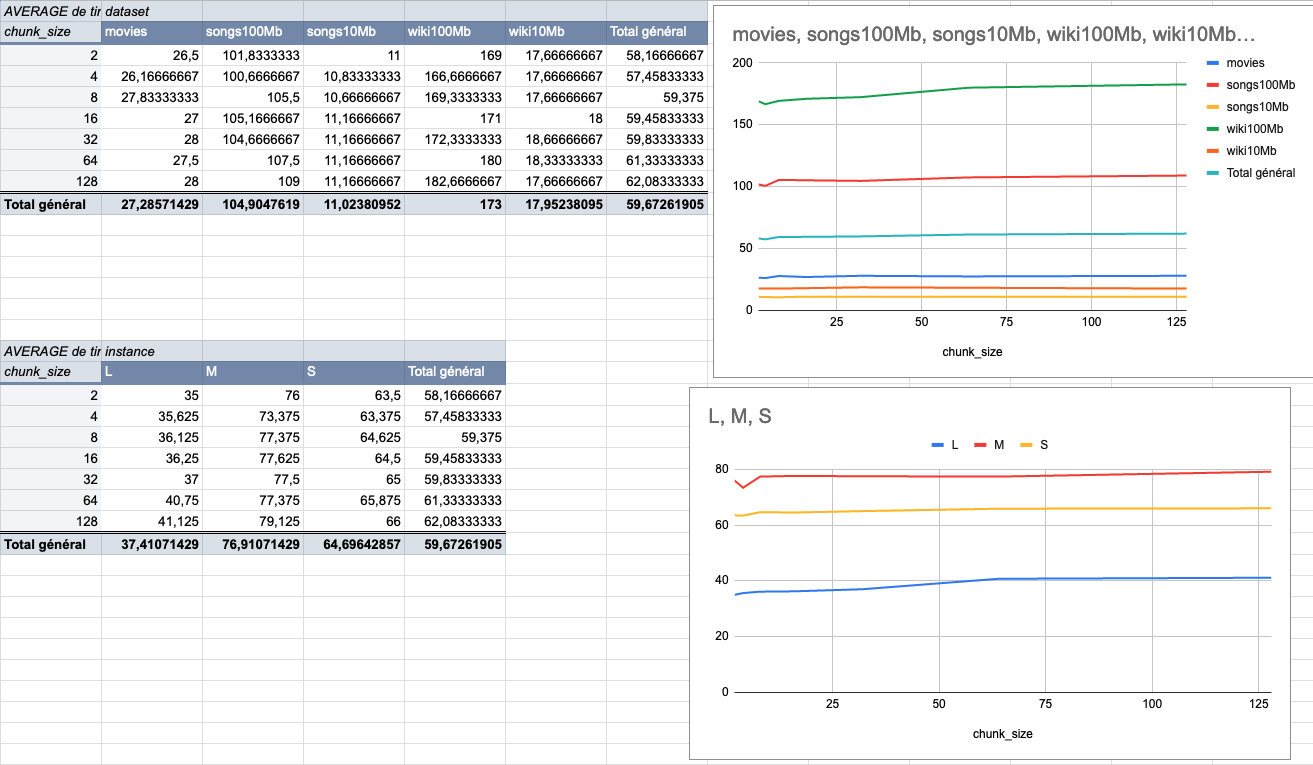 </br> </details> Co-authored-by: Many <many@meilisearch.com>
{kind=link}
{kind=link}
This commit is contained in:
commit
fda4f229bb
@ -243,7 +243,7 @@ where
|
||||
let chunk_iter = grenad_obkv_into_chunks(
|
||||
documents_file,
|
||||
params.clone(),
|
||||
self.indexer_config.documents_chunk_size.unwrap_or(1024 * 1024 * 128), // 128MiB
|
||||
self.indexer_config.documents_chunk_size.unwrap_or(1024 * 1024 * 4), // 4MiB
|
||||
);
|
||||
|
||||
let result = chunk_iter.map(|chunk_iter| {
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user