2005: auto batching r=MarinPostma a=MarinPostma This pr implements auto batching. The basic functioning of this is that all updates that can be batched together are batched together while the previous batch is being processed. For now, the only updates that can be batched together are the document addition updates (both update and replace), for a single index. The batching is disabled by default for multiple reasons: - We need more experimentation with the scheduling techniques - Right now, if one task fails in a batch, the whole batch fails. We need more permissive error handling when processing document indexation. There are four CLI options, for now, to interact with how the batch is scheduled: - `enable-autobatching`: enable the autobatching feature. - `debounce-duration-sec`: When an update is received, wait that number of seconds before batching and performing the updates. Defaults to 0s. - `max-batch-size`: the maximum number of tasks per batch, defaults to unlimited. - `max-documents-per-batch`: the maximum number of documents in a batch, defaults to unlimited. The batch will always contain a least 1 task, no matter the number of documents in that task. # Implementation The current implementation is made of 3 major components: ## TaskStore The `TaskStore` contains all the tasks. When a task is pushed, it is directly registered to the task store. ## Scheduler The scheduler is in charge of making the batches. At its core, there is a `TaskQueue` and a job queue. `Job`s are always processed first. They are *volatile* tasks, that is, they don't have a TaskId and are not persisted to disk. Snapshots and dumps are examples of Jobs. If no `Job` is available for processing, then the scheduler attempts to make a `Task` batch from the `TaskQueue`. The first step is to gather new tasks from the `TaskStore` to populate the `TaskQueue`. When this is done, we can prepare our batch. The `TaskQueue` is itself a `BinaryHeap` of `Tasklist`. Each `index_uid` is associated with a `TaskList` that contains all the updates associated with that index uid. Each `TaskList` in the `TaskQueue` is ordered by the id of its first task. When preparing a batch, the `TaskList` at the top of the `TaskQueue` is popped, and the tasks are popped from the list to make the next batch. If there are remaining tasks in the list, the list is inserted back in the `TaskQueue`. ## UpdateLoop The `UpdateLoop` role is to perform batch sequentially. Each time updates are pushed to the update store, the scheduler is notified, and will in turn notify the update loop that work can be performed. When notified, the update loop waits some time to wait for more incoming update and then asks the scheduler for the next batch to perform and perform it. When it is done, the status of the task is put back into the store, and the next batch is processed. Co-authored-by: mpostma <postma.marin@protonmail.com>
![]()
Meilisearch
Website | Roadmap | Blog | LinkedIn | Twitter | Documentation | FAQ
![]()

![]()
![]()
⚡ Lightning Fast, Ultra Relevant, and Typo-Tolerant Search Engine 🔍
Meilisearch is a powerful, fast, open-source, easy to use and deploy search engine. Both searching and indexing are highly customizable. Features such as typo-tolerance, filters, and synonyms are provided out-of-the-box. For more information about features go to our documentation.
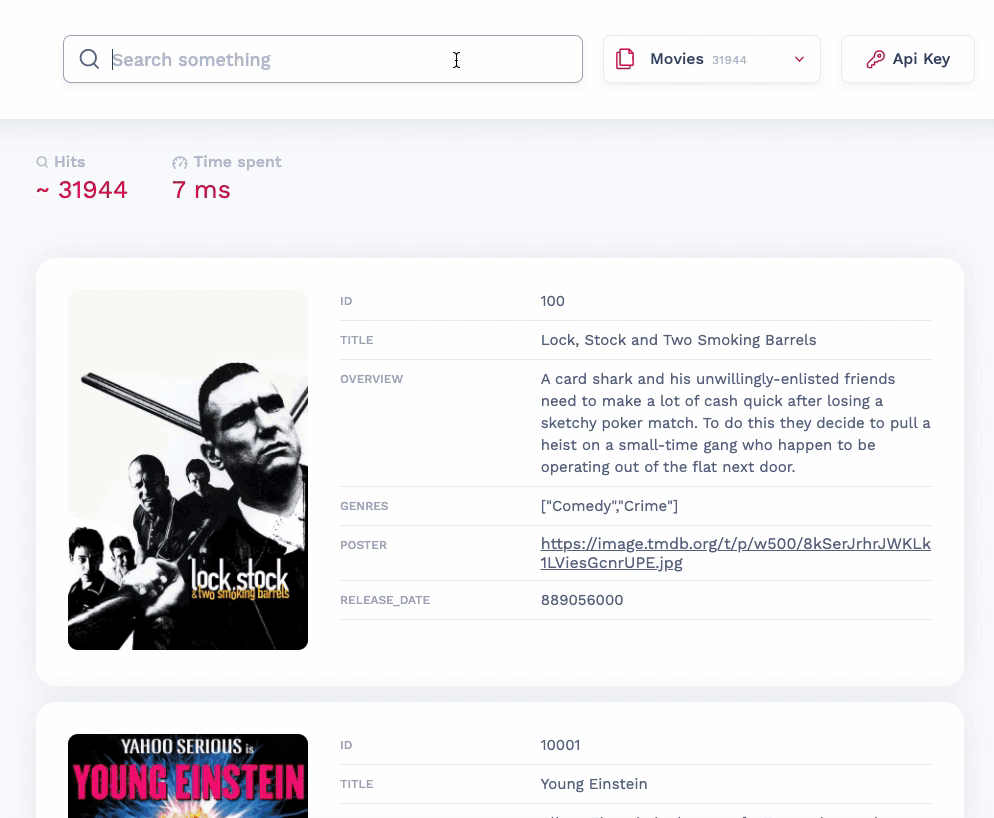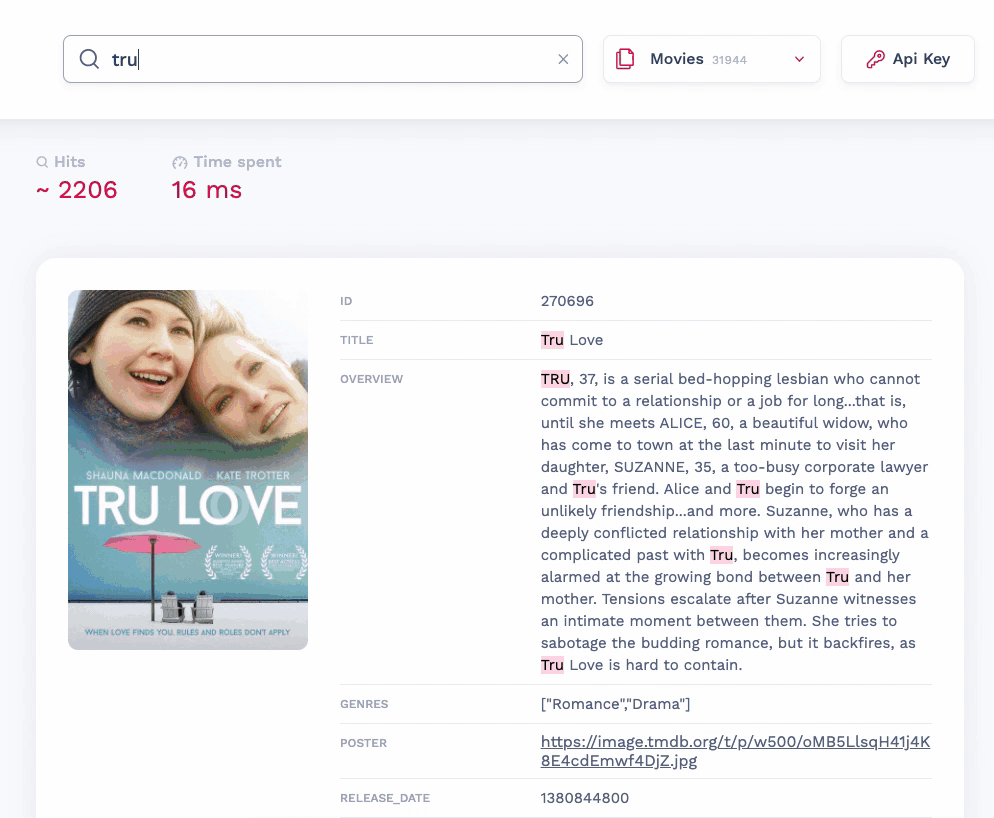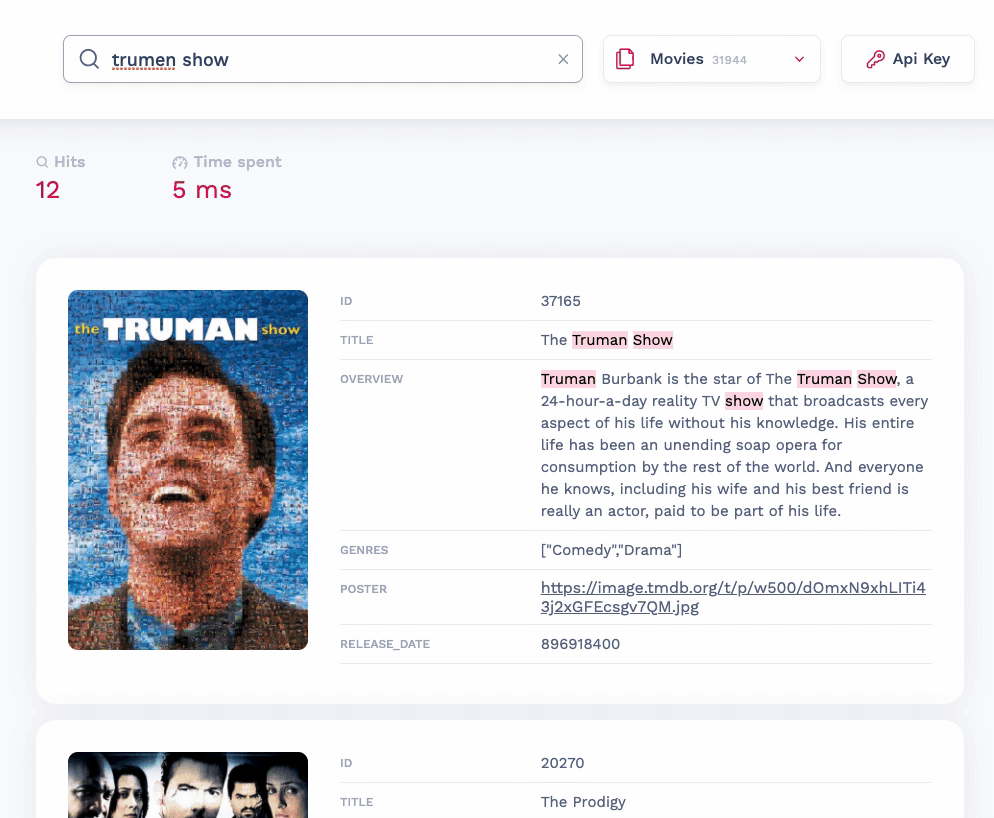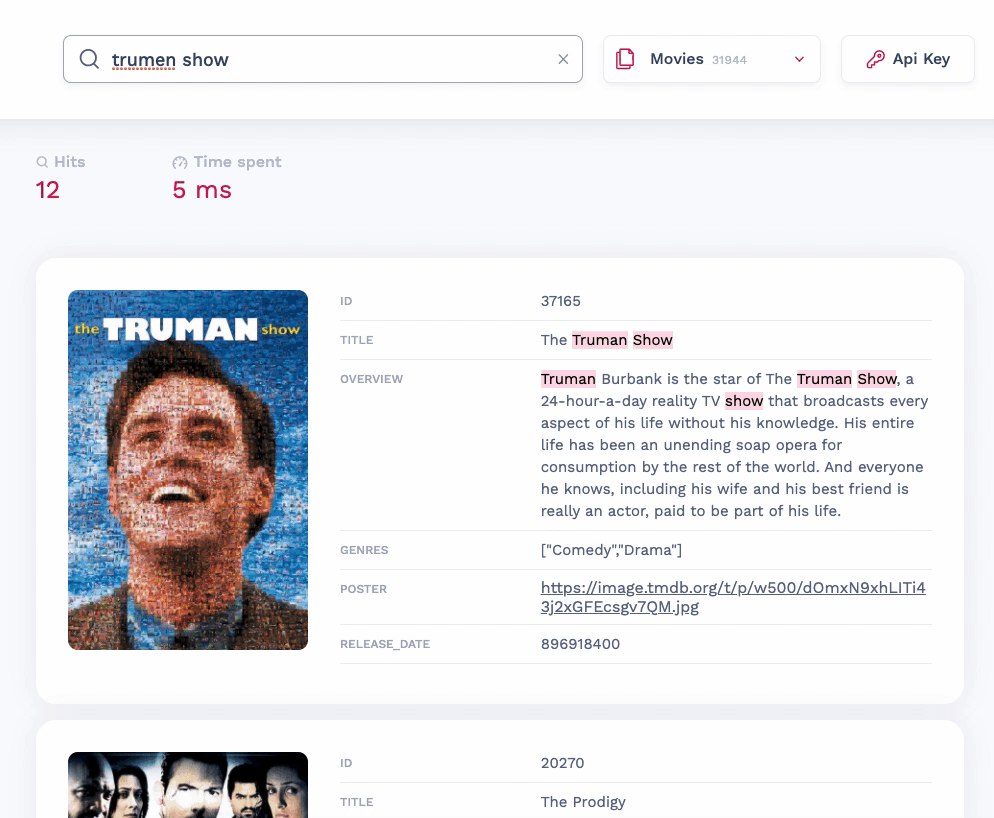
✨ Features
- Search-as-you-type experience (answers < 50 milliseconds)
- Full-text search
- Typo tolerant (understands typos and misspelling)
- Faceted search and filters
- Supports hanzi (Chinese characters)
- Supports synonyms
- Easy to install, deploy, and maintain
- Whole documents are returned
- Highly customizable
- RESTful API
Getting started
Deploy the Server
Homebrew (Mac OS)
brew update && brew install meilisearch
meilisearch
Docker
docker run -p 7700:7700 -v "$(pwd)/data.ms:/data.ms" getmeili/meilisearch
Announcing a cloud-hosted Meilisearch
Join the closed beta by filling out this form.
Try Meilisearch in our Sandbox
Create a Meilisearch instance in Meilisearch Sandbox. This instance is free, and will be active for 48 hours.
Run on Digital Ocean

Deploy on Platform.sh

APT (Debian & Ubuntu)
echo "deb [trusted=yes] https://apt.fury.io/meilisearch/ /" > /etc/apt/sources.list.d/fury.list
apt update && apt install meilisearch-http
meilisearch
Download the binary (Linux & Mac OS)
curl -L https://install.meilisearch.com | sh
./meilisearch
Compile and run it from sources
If you have the latest stable Rust toolchain installed on your local system, clone the repository and change it to your working directory.
git clone https://github.com/meilisearch/meilisearch.git
cd meilisearch
cargo run --release
Create an Index and Upload Some Documents
Let's create an index! If you need a sample dataset, use this movie database. You can also find it in the datasets/ directory.
curl -L 'https://bit.ly/2PAcw9l' -o movies.json
Now, you're ready to index some data.
curl -i -X POST 'http://127.0.0.1:7700/indexes/movies/documents' \
--header 'content-type: application/json' \
--data-binary @movies.json
Search for Documents
In command line
The search engine is now aware of your documents and can serve those via an HTTP server.
The jq command-line tool can greatly help you read the server responses.
curl 'http://127.0.0.1:7700/indexes/movies/search?q=botman+robin&limit=2' | jq
{
"hits": [
{
"id": "415",
"title": "Batman & Robin",
"poster": "https://image.tmdb.org/t/p/w1280/79AYCcxw3kSKbhGpx1LiqaCAbwo.jpg",
"overview": "Along with crime-fighting partner Robin and new recruit Batgirl, Batman battles the dual threat of frosty genius Mr. Freeze and homicidal horticulturalist Poison Ivy. Freeze plans to put Gotham City on ice, while Ivy tries to drive a wedge between the dynamic duo.",
"release_date": 866768400
},
{
"id": "411736",
"title": "Batman: Return of the Caped Crusaders",
"poster": "https://image.tmdb.org/t/p/w1280/GW3IyMW5Xgl0cgCN8wu96IlNpD.jpg",
"overview": "Adam West and Burt Ward returns to their iconic roles of Batman and Robin. Featuring the voices of Adam West, Burt Ward, and Julie Newmar, the film sees the superheroes going up against classic villains like The Joker, The Riddler, The Penguin and Catwoman, both in Gotham City… and in space.",
"release_date": 1475888400
}
],
"nbHits": 8,
"exhaustiveNbHits": false,
"query": "botman robin",
"limit": 2,
"offset": 0,
"processingTimeMs": 2
}
Use the Web Interface
We also deliver an out-of-the-box web interface in which you can test Meilisearch interactively.
You can access the web interface in your web browser at the root of the server. The default URL is http://127.0.0.1:7700. All you need to do is open your web browser and enter Meilisearch’s address to visit it. This will lead you to a web page with a search bar that will allow you to search in the selected index.
Documentation
Now that your Meilisearch server is up and running, you can learn more about how to tune your search engine in the documentation.
Contributing
Hey! We're glad you're thinking about contributing to Meilisearch! Feel free to pick an issue labeled as good first issue, and to ask any question you need. Some points might not be clear and we are available to help you!
Also, we recommend following the CONTRIBUTING to create your PR.
Core engine and tokenizer
The code in this repository is only concerned with managing multiple indexes, handling the update store, and exposing an HTTP API.
Search and indexation are the domain of our core engine, milli, while tokenization is handled by our tokenizer library.
Telemetry
Meilisearch collects anonymous data regarding general usage. This helps us better understand developers' usage of Meilisearch features.
To find out more on what information we're retrieving, please see our documentation on Telemetry.
This program is optional, you can disable these analytics by using the MEILI_NO_ANALYTICS env variable.
Feature request
The feature requests are not managed in this repository. Please visit our dedicated repository to see our work about the Meilisearch product.
If you have a feature request or any feedback about an existing feature, please open a discussion. Also, feel free to participate in the current discussions, we are looking forward to reading your comments.
💌 Contact
Please visit this page.
Meilisearch is developed by Meili, a young company. To know more about us, you can read our blog. Any suggestion or feedback is highly appreciated. Thank you for your support!