1965: Reintroduce engine version file r=MarinPostma a=irevoire
Right now if you boot up MeiliSearch and point it to a DB directory created with a previous version of MeiliSearch the existing indexes will be deleted. This [used to be](51d7c84e73) prevented by a startup check which would compare the current engine version vs what was stored in the DB directory's version file, but this functionality seems to have been lost after a few refactorings of the code.
In order to go back to the old behavior we'll need to reintroduce the `VERSION` file that used to be present; I considered reusing the `metadata.json` file used in the dumps feature, but this seemed like the simpler and more approach. As the intent is just to restore functionality, the implementation is quite basic. I imagine that in the future we could build on this and do things like compatibility across major/minor versions and even migrating between formats.
This PR was made thanks to `@mbStavola` and is basically a port of his PR #1860 after a big refacto of the code #1796.
Closes#1840
Co-authored-by: Matt Stavola <m.freitas@offensive-security.com>
Right now if you boot up MeiliSearch and point it to a DB directory created with a previous version of MeiliSearch the existing indexes will be deleted. This used to be prevented by a startup check which would compare the current engine version vs what was stored in the DB directory's version file, but this functionality seems to have been lost after a few refactorings of the code.
In order to go back to the old behavior we'll need to reintroduce the VERSION file that used to be present; I considered reusing the metadata.json file used in the dumps feature, but this seemed like the simpler and more approach. As the intent is just to restore functionality, the implementation is quite basic. I imagine that in the future we could build on this and do things like compatibility across major/minor versions and even migrating between formats.
This PR was made thanks to @mbStavola
Closes#1840
implements:
https://github.com/meilisearch/specifications/blob/develop/text/0085-api-keys.md
- Add tests on API keys management route (meilisearch-http/tests/auth/api_keys.rs)
- Add tests checking authorizations on each meilisearch routes (meilisearch-http/tests/auth/authorization.rs)
- Implement API keys management routes (meilisearch-http/src/routes/api_key.rs)
- Create module to manage API keys and authorizations (meilisearch-auth)
- Reimplement GuardedData to extend authorizations (meilisearch-http/src/extractors/authentication/mod.rs)
- Change X-MEILI-API-KEY by Authorization Bearer (meilisearch-http/src/extractors/authentication/mod.rs)
- Change meilisearch routes to fit to the new authorization feature (meilisearch-http/src/routes/)
- close#1867
1796: Feature branch: Task store r=irevoire a=MarinPostma
# Feature branch: Task Store
## Spec todo
https://github.com/meilisearch/specifications/blob/develop/text/0060-refashion-updates-apis.md
- [x] The update resource is renamed task. The names of existing API routes are also changed to reflect this change.
- [x] Tasks are now also accessible as an independent resource of an index. GET - /tasks; GET - /tasks/:taskUid
- [x] The task uid is not incremented by index anymore. The sequence is generated globally.
- [x] A task_not_found error is introduced.
- [x] The format of the task object is updated.
- [x] updateId becomes uid.
- [x] Attributes of an error appearing in a failed task are now contained in a dedicated error object.
- [x] type is no longer an object. It now becomes a string containing the values of its name field previously defined in the type object.
- [x] The possible values for the type field are reworked to be more clear and consistent with our naming rules.
- [x] A details object is added to contain specific information related to a task payload that was previously displayed in the type nested object. Previous number key is renamed numberOfDocuments.
- [x] An indexUid field is added to give information about the related index on which the task is performed.
- [x] duration format has been updated to express an ISO 8601 duration.
- [x] processed status changes to succeeded.
- [x] startedProcessingAt is updated to startedAt.
- [x] processedAt is updated to finishedAt.
- [x] 202 Accepted requests previously returning an updateId are now returning a summarized task object.
- [x] MEILI_MAX_UDB_SIZE env var is updated MEILI_MAX_TASK_DB_SIZE.
- [x] --max-udb-size cli option is updated to --max-task-db-size.
- [x] task object lists are now returned under a results array.
- [x] Each operation on an index (creation, update, deletion) is now asynchronous and represented by a task.
## Todo tech
- [x] Restore Snapshots
- [x] Restore dumps of documents
- [x] Implements the dump of updates
- [x] Error handling
- [x] Fix stats
- [x] Restore the Analytics
- [x] [Add the new analytics](https://github.com/meilisearch/specifications/pull/92/files)
- [x] Fix tests
- [x] ~Deleting tasks when index is deleted (see bellow)~ see #1891 instead
- [x] Improve details for documents addition and deletion tasks
- [ ] Add integration test
- [ ] Test task store filtering
- [x] Rename `UuidStore` to `IndexMetaStore`, and simplify the trait.
- [x] Fix task store initialization: fill pending queue from hard state
- [x] Synchronously return error when creating an index with an invalid index_uid and add test
- [x] Task should be returned in decreasing uid + tests (on index task route)
- [x] Summarized task view
- [x] fix snapshot permissions
## Implementation
### Linked PRs
- #1889
- #1891
- #1892
- #1902
- #1906
- #1911
- #1914
- #1915
- #1916
- #1918
- #1924
- #1925
- #1926
- #1930
- #1936
- #1937
- #1942
- #1944
- #1945
- #1946
- #1947
- #1950
- #1951
- #1957
- #1959
- #1960
- #1961
- #1962
- #1964
### Linked PRs in milli:
- https://github.com/meilisearch/milli/pull/414
- https://github.com/meilisearch/milli/pull/409
- https://github.com/meilisearch/milli/pull/406
- https://github.com/meilisearch/milli/pull/418
### Issues
- close#1687
- close#1786
- close#1940
- close#1948
- close#1949
- close#1932
- close#1956
### Spec patches
- https://github.com/meilisearch/specifications/pull/90
Co-authored-by: Marin Postma <postma.marin@protonmail.com>
1893: Make matches work with numerical value r=MarinPostma a=Thearas
# Pull Request
## What does this PR do?
Implement #1883.
I have test this PR with unit test. It appears to be working properly:
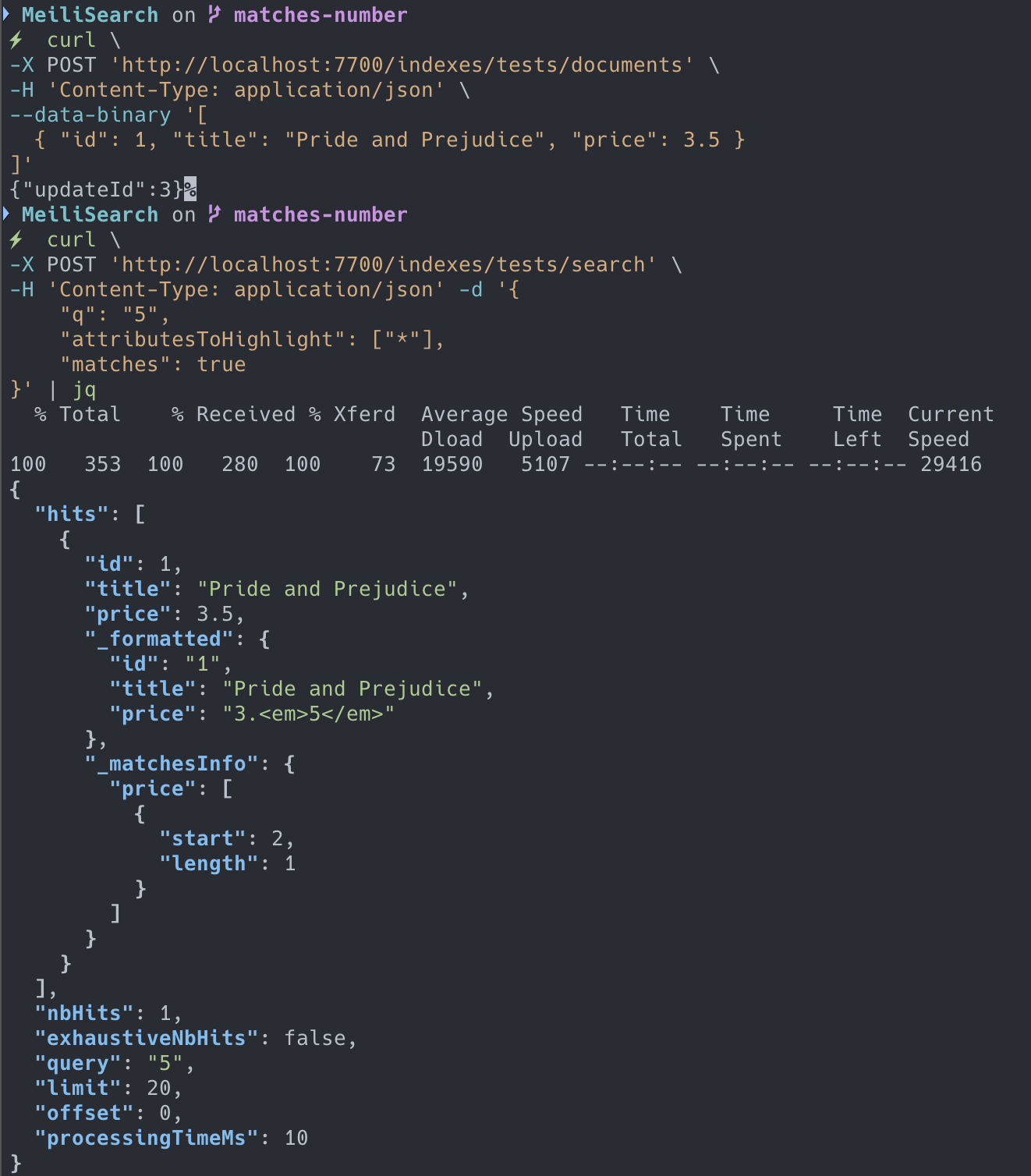
PTAL `@curquiza`
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
Co-authored-by: Thearas <thearas850@gmail.com>
1896: Remove email address from the message at the launch r=irevoire a=curquiza
I suggest removing this email address from the message at the launch since it can encourage people to think this is an email address for support. Is it something we want `@meilisearch/devrel-team` since we mostly redirect them to the forum or the slack?
Co-authored-by: Clémentine Urquizar <clementine@meilisearch.com>
1904: Update mini-dashboard version to v0.1.5 r=curquiza a=curquiza
Update the mini-dashboard with its latest version (v0.1.5)
Check with `@mdubus,` replaces https://github.com/meilisearch/MeiliSearch/pull/1903Fixes#1898
Co-authored-by: Clémentine Urquizar <clementine@meilisearch.com>
1897: Add ARM image for Docker to CI r=irevoire a=curquiza
Fixes#1315
- [x] Publish MeiliSearch's docker image for `arm64`
- [x] Add `workflow_dispatch` event in case we need to re-trigger it after a failure without creating a new release
- [x] Use our own server to run the github runner since this CI is really slow (1h instead of 4h)
- [x] Open an issue for a refactor by merging both files in one file (https://github.com/meilisearch/MeiliSearch/issues/1901)
Co-authored-by: Clémentine Urquizar <clementine@meilisearch.com>
1882: Remove release drafter r=curquiza a=curquiza
Remove release drafter since it's not used at the moment due to the specific release process of MeiliSearch.
Co-authored-by: Clémentine Urquizar <clementine@meilisearch.com>
1878: Add error object in task r=MarinPostma a=ManyTheFish
# Pull Request
## What does this PR do?
Fixes#1877
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Update error test
- [x] Remove flattening of errors during task serialization
Co-authored-by: many <maxime@meilisearch.com>
1875: Fix search post event and disk size analytics r=irevoire a=gmourier
- Branch POST search on the post_search aggregator
- Use largest disk `total_space` instead of `available_space`
1876: Update SEGMENT_API_KEY r=irevoire a=gmourier
Branch it on our Segment production stack
Co-authored-by: Guillaume Mourier <guillaume@meilisearch.com>
1800: Analytics r=irevoire a=irevoire
Closes#1784
Implements [this spec](https://github.com/meilisearch/specifications/blob/update-analytics-specs/text/0034-telemetry-policies.md)
# Anonymous Analytics Policy
## 1. Functional Specification
### I. Summary
This specification describes an exhaustive list of anonymous metrics collected by the MeiliSearch binary. It also describes the tools we use for this collection and how we identify a Meilisearch instance.
### II. Motivation
At MeiliSearch, our vision is to provide an easy-to-use search solution that meets the essential needs of our users. At all times, we strive to understand our users better and meet their expectations in the best possible way.
Although we can gather needs and understand our users through several channels such as Github, Slack, surveys, interviews or roadmap votes, we realize that this is not enough to have a complete view of MeiliSearch usage and features adoption. By cross-referencing our product discovery phases with aggregated quantitative data, we want to make the product much better than what it is today. Our decision-making will be taken a step further to make a product that users love.
### III. Explanation
#### General Data Protection Regulation (GDPR)
The metrics collected are non-sensitive, non-personal and do not identify an individual or a group of individuals using MeiliSearch. The data collected is secured and anonymized. We do not collect any data from the values stored in the documents.
We, the MeiliSearch team, provide an email address so that users can request the removal of their data: privacy@meilisearch.com.<br>
Thanks to the unique identifier generated for their MeiliSearch installation (`Instance uuid` when launching MeiliSearch), we can remove the corresponding data from all the tools we describe below. Any questions regarding the management of the data collected can be sent to the email address as well.
#### Tools
##### Segment
The collected data is sent to [Segment](https://segment.com/). Segment is a platform for data collection and provides data management tools.
##### Amplitude
[Amplitude](https://amplitude.com/) is a tool for graphing and highlighting collected data. Segment feeds Amplitude so that we can build visualizations according to our needs.
-----------
# The `identify` call we send every hour:
## System Configuration `system`
This property allows us to gather essential information to better understand on which type of machine MeiliSearch is used. This allows us to better advise users on the machines to choose according to their data volume and their use-cases.
- [x] `system` => Never changes but still sent every hours
- [x] distribution | On which distribution MeiliSearch is launched, eg: Arch Linux
- [x] kernel_version | On which kernel version MeiliSearch is launched, eg: 5.14.10-arch1-1
- [x] cores | How many cores does the machine have, eg: 24
- [x] ram_size | Total capacity of the machine's ram. Expressed in `Kb`, eg: 33604210
- [x] disk_size | Total capacity of the biggest disk. Expressed in `Kb`, eg: 336042103
- [x] server_provider | Users can tell us on which provider MeiliSearch is hosted by filling the `MEILI_SERVER_PROVIDER` env var. This is also filled by our providers deploy scripts. e.g. GCP [cloud-config.yaml](56a7c2630c/scripts/providers/gcp/cloud-config.yaml (L33)), eg: gcp
## MeiliSearch Configuration
- [x] `context.app.version`: MeiliSearch version, eg: 0.23.0
- [x] `env`: `production` / `development`, eg: `production`
- [x] `has_snapshot`: Does the MeiliSearch instance has snapshot activated, eg: `true`
## MeiliSearch Statistics `stats`
- [x] `stats`
- [x] `database_size`: Size of indexed data. Expressed in `Kb`, eg: 180230
- [x] `indexes_number`: Number of indexes, eg: 2
- [x] `documents_number`: Number of indexed documents, eg: 165847
- [x] `start_since_days`: How many days ago was the instance launched?, eg: 328
---------
- [x] Launched | This is the first event sent to mark that MeiliSearch is launched a first time
---------
- [x] `Documents Searched POST`: The Documents Searched event is sent once an hour. The event's properties are averaged over all search operations during that time so as not to track everything and generate unnecessary noise.
- [x] `user-agent`: Represents all the user-agents encountered on this endpoint during one hour, eg: `["MeiliSearch Ruby (2.1)", "Ruby (3.0)"]`
- [x] `requests`
- [x] `99th_response_time`: The maximum latency, in ms, for the fastest 99% of requests, eg: `57ms`
- [x] `total_suceeded`: The total number of succeeded search requests, eg: `3456`
- [x] `total_failed`: The total number of failed search requests, eg: `24`
- [x] `total_received`: The total number of received search requests, eg: `3480`
- [x] `sort`
- [x] `with_geoPoint`: Does the built-in sort rule _geoPoint rule has been used?, eg: `true` /`false`
- [x] `avg_criteria_number`: The average number of sort criteria among all the requests containing the sort parameter. "sort": [] equals to 0 while not sending sort does not influence the average, eg: `2`
- [x] `filter`
- [x] `with_geoRadius`: Does the built-in filter rule _geoRadius has been used?, eg: `true` /`false`
- [x] `avg_criteria_number`: The average number of filter criteria among all the requests containing the filter parameter. "filter": [] equals to 0 while not sending filter does not influence the average, eg: `4`
- [x] `most_used_syntax`: The most used filter syntax among all the requests containing the requests containing the filter parameter. `string` / `array` / `mixed`, `mixed`
- [x] `q`
- [x] `avg_terms_number`: The average number of terms for the `q` parameter among all requests, eg: `5`
- [x] `pagination`:
- [x] `max_limit`: The maximum limit encountered among all requests, eg: `20`
- [x] `max_offset`: The maxium offset encountered among all requests, eg: `1000`
---
- [x] `Documents Searched GET`: The Documents Searched event is sent once an hour. The event's properties are averaged over all search operations during that time so as not to track everything and generate unnecessary noise.
- [x] `user-agent`: Represents all the user-agents encountered on this endpoint during one hour, eg: `["MeiliSearch Ruby (2.1)", "Ruby (3.0)"]`
- [x] `requests`
- [x] `99th_response_time`: The maximum latency, in ms, for the fastest 99% of requests, eg: `57ms`
- [x] `total_suceeded`: The total number of succeeded search requests, eg: `3456`
- [x] `total_failed`: The total number of failed search requests, eg: `24`
- [x] `total_received`: The total number of received search requests, eg: `3480`
- [x] `sort`
- [x] `with_geoPoint`: Does the built-in sort rule _geoPoint rule has been used?, eg: `true` /`false`
- [x] `avg_criteria_number`: The average number of sort criteria among all the requests containing the sort parameter. "sort": [] equals to 0 while not sending sort does not influence the average, eg: `2`
- [x] `filter`
- [x] `with_geoRadius`: Does the built-in filter rule _geoRadius has been used?, eg: `true` /`false`
- [x] `avg_criteria_number`: The average number of filter criteria among all the requests containing the filter parameter. "filter": [] equals to 0 while not sending filter does not influence the average, eg: `4`
- [x] `most_used_syntax`: The most used filter syntax among all the requests containing the requests containing the filter parameter. `string` / `array` / `mixed`, `mixed`
- [x] `q`
- [x] `avg_terms_number`: The average number of terms for the `q` parameter among all requests, eg: `5`
- [x] `pagination`:
- [x] `max_limit`: The maximum limit encountered among all requests, eg: `20`
- [x] `max_offset`: The maxium offset encountered among all requests, eg: `1000`
---
- [x] `Index Created`
- [x] `user-agent`: Represents the user-agent encountered for this API call, eg: ["MeiliSearch Ruby (2.1)", "Ruby (3.0)"]
- [x] `primary_key`: The name of the field used as primary key if set, otherwise `null`, eg: `id`
---
- [x] `Index Updated`
- [x] `user-agent`: Represents the user-agent encountered for this API call, eg: ["MeiliSearch Ruby (2.1)", "Ruby (3.0)"]
- [x] `primary_key`: The name of the field used as primary key if set, otherwise `null`, eg: `id`
---
- [x] `Documents Added`: The Documents Added event is sent once an hour. The event's properties are averaged over all POST /documents additions operations during that time to not track everything and generate unnecessary noise.
- [x] `user-agent`: Represents the user-agent encountered for this API call, eg: ["MeiliSearch Ruby (2.1)", "Ruby (3.0)"]
- [x] `payload_type`: Represents all the `payload_type` encountered on this endpoint during one hour, eg: [`text/csv`]
- [x] `primary_key`: The name of the field used as primary key if set, otherwise `null`, eg: `id`
- [x] `index_creation`: Does an index creation happened, eg: `false`
---
- [x] `Documents Updated`: The Documents Added event is sent once an hour. The event's properties are averaged over all PUT /documents additions operations during that time to not track everything and generate unnecessary noise.
- [x] `user-agent`: Represents the user-agent encountered for this API call, eg: ["MeiliSearch Ruby (2.1)", "Ruby (3.0)"]
- [x] `payload_type`: Represents all the `payload_type` encountered on this endpoint during one hour, eg: [`application/json`]
- [x] `primary_key`: The name of the field used as primary key if set, otherwise `null`, eg: `id`
- [x] `index_creation`: Does an index creation happened, eg: `false`
---
- [x] Settings Updated
- [x] `user-agent`: Represents the user-agent encountered for this API call, eg: ["MeiliSearch Ruby (2.1)", "Ruby (3.0)"]
- [x] `ranking_rules`
- [x] `sort_position`: Position of the `sort` ranking rule if any, otherwise `null`, eg: `5`
- [x] `sortable_attributes`
- [x] `total`: Number of sortable attributes, eg: `3`
- [x] `has_geo`: Indicate if `_geo` is set as a sortable attribute, eg: `false`
- [x] `filterable_attributes`
- [x] `total`: Number of filterable attributes, eg: `3`
- [x] `has_geo`: Indicate if `_geo` is set as a filterable attribute, eg: `false`
---
- [x] `RankingRules Updated`
- [x] `user-agent`: Represents the user-agent encountered for this API call, eg: ["MeiliSearch Ruby (2.1)", "Ruby (3.0)"]
- [x] `sort_position`: Position of the `sort` ranking rule if any, otherwise `null`, eg: `5`
---
- [x] `SortableAttributes Updated`
- [x] `user-agent`: Represents the user-agent encountered for this API call, eg: ["MeiliSearch Ruby (2.1)", "Ruby (3.0)"]
- [x] `total`: Number of sortable attributes, eg: `3`
- [x] `has_geo`: Indicate if `_geo` is set as a sortable attribute, eg: `false`
---
- [x] `FilterableAttributes Updated`
- [x] `user-agent`: Represents the user-agent encountered for this API call, eg: ["MeiliSearch Ruby (2.1)", "Ruby (3.0)"]
- [x] `total`: Number of filterable attributes, eg: `3`
- [x] `has_geo`: Indicate if `_geo` is set as a filterable attribute, eg: `false`
---
- [x] Dump Created
- [x] `user-agent`: Represents the user-agent encountered for this API call, eg: ["MeiliSearch Ruby (2.1)", "Ruby (3.0)"]
---
Ensure the user-id file is well saved and loaded with:
- [x] the dumps
- [x] the snapshots
- [x] Ensure the CLI uuid only show if analytics are activate at launch **or already exists** (=even if meilisearch was launched without analytics)
Co-authored-by: Tamo <tamo@meilisearch.com>
Co-authored-by: Irevoire <tamo@meilisearch.com>
{kind=link}