438: CLI improvements r=Kerollmops a=MarinPostma
I've made the following changes to the cli:
- `settings-update` become `settings`, with two subcommands: `update` and `show`.
- `document-addition` becomes `documents` with a subcommands: `add` (I'll add a feature to list documents later)
- `search` now has an interactive mode `-i`
- search return the number of documents and the time it took to perform the search.
Co-authored-by: mpostma <postma.marin@protonmail.com>
430: Document batch support r=Kerollmops a=MarinPostma
This pr adds support for document batches in milli. It changes the API of the `IndexDocuments` builder by adding a `add_documents` method. The API of the updates is changed a little, with the `UpdateBuilder` being renamed to `IndexerConfig` and being passed to the update builders. This makes it easier to pass around structs that need to access the indexer config, rather that extracting the fields each time. This change impacts many function signatures and simplify them.
The change in not thorough, and may require another PR to propagate to the whole codebase. I restricted to the necessary for this PR.
Co-authored-by: Marin Postma <postma.marin@protonmail.com>
433: fix(filter): Fix two bugs. r=Kerollmops a=irevoire
- Stop lowercasing the field when looking in the field id map
- When a field id does not exist it means there is currently zero
documents containing this field thus we return an empty RoaringBitmap
instead of throwing an internal error
Will fix https://github.com/meilisearch/MeiliSearch/issues/2082 once meilisearch is released
Co-authored-by: Tamo <tamo@meilisearch.com>
426: Fix search highlight for non-unicode chars r=ManyTheFish a=Samyak2
# Pull Request
## What does this PR do?
Fixes https://github.com/meilisearch/MeiliSearch/issues/1480
<!-- Please link the issue you're trying to fix with this PR, if none then please create an issue first. -->
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue?
- [x] Have you read the contributing guidelines?
- [x] Have you made sure that the title is accurate and descriptive of the changes?
## Changes
The `matching_bytes` function takes a `&Token` now and:
- gets the number of bytes to highlight (unchanged).
- uses `Token.num_graphemes_from_bytes` to get the number of grapheme clusters to highlight.
In essence, the `matching_bytes` function now returns the number of matching grapheme clusters instead of bytes.
Added proper highlighting in the HTTP UI:
- requires dependency on `unicode-segmentation` to extract grapheme clusters from tokens
- `<mark>` tag is put around only the matched part
- before this change, the entire word was highlighted even if only a part of it matched
## Questions
Since `matching_bytes` does not return number of bytes but grapheme clusters, should it be renamed to something like `matching_chars` or `matching_graphemes`? Will this break the API?
Thank you very much `@ManyTheFish` for helping 😄
Co-authored-by: Samyak S Sarnayak <samyak201@gmail.com>
- Stop lowercasing the field when looking in the field id map
- When a field id does not exist it means there is currently zero
documents containing this field thus we returns an empty RoaringBitmap
instead of throwing an internal error
432: Fuzzer r=Kerollmops a=irevoire
Provide a first way of fuzzing the indexing part of milli.
It depends on [cargo-fuzz](https://rust-fuzz.github.io/book/cargo-fuzz.html)
Co-authored-by: Tamo <tamo@meilisearch.com>
The `matching_bytes` function takes a `&Token` now and:
- gets the number of bytes to highlight (unchanged).
- uses `Token.num_graphemes_from_bytes` to get the number of grapheme
clusters to highlight.
In essence, the `matching_bytes` function returns the number of matching
grapheme clusters instead of bytes. Should this function be renamed
then?
Added proper highlighting in the HTTP UI:
- requires dependency on `unicode-segmentation` to extract grapheme
clusters from tokens
- `<mark>` tag is put around only the matched part
- before this change, the entire word was highlighted even if only a
part of it matched
424: Store the geopoint in three dimensions r=Kerollmops a=irevoire
Related to this issue: https://github.com/meilisearch/MeiliSearch/issues/1872
Fix the whole computation of distance for any “geo” operations (sort or filter). Now when you sort points they are returned to you in the right order.
And when you filter on a specific radius you only get points included in the radius.
This PR changes the way we store the geo points in the RTree.
Instead of considering the latitude and longitude as orthogonal coordinates, we convert them to real orthogonal coordinates projected on a sphere with a radius of 1.
This is the conversion formulae.
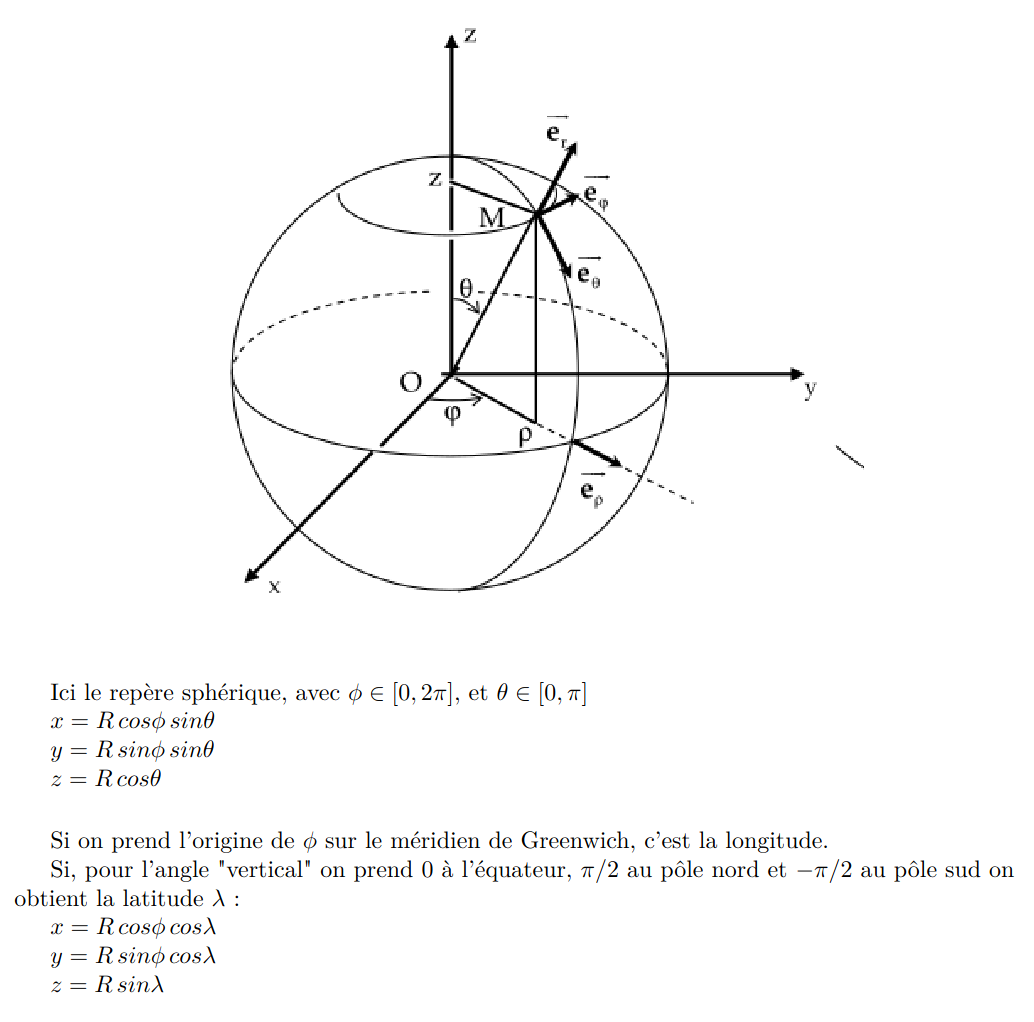
Which, in rust, translate to this function:
```rust
pub fn lat_lng_to_xyz(coord: &[f64; 2]) -> [f64; 3] {
let [lat, lng] = coord.map(|f| f.to_radians());
let x = lat.cos() * lng.cos();
let y = lat.cos() * lng.sin();
let z = lat.sin();
[x, y, z]
}
```
Storing the points on a sphere is easier / faster to compute than storing the point on an approximation of the real earth shape.
But when we need to compute the distance between two points we still need to use the haversine distance which works with latitude and longitude.
So, to do the fewest search-time computation possible I'm now associating every point with its `DocId` and its lat/lng.
Co-authored-by: Tamo <tamo@meilisearch.com>
429: Benchmark CIs: not use a default label to call the GH runner r=irevoire a=curquiza
Since we now have multiple self-hosted github runners, we need to differentiate them calling them in the CI. The `self-hosted` label is the default one, so we need to use the unique and appropriate one for the benchmark machine
<img width="925" alt="Capture d’écran 2022-01-04 à 15 42 18" src="https://user-images.githubusercontent.com/20380692/148079840-49cd7878-5912-46ff-8ab8-bf646777f782.png">
Co-authored-by: Clémentine Urquizar <clementine@meilisearch.com>
428: Reintroduce the gitignore for the fuzzer r=Kerollmops a=irevoire
Reintroduce the gitignore in the fuzz directory
Co-authored-by: Tamo <tamo@meilisearch.com>
425: Push the result of the benchmarks to influxdb r=irevoire a=irevoire
Now execute a benchmark for every PR merged into main and then upload the results to influxdb.
Co-authored-by: Tamo <tamo@meilisearch.com>
422: Prefer returning `None` instead of using an `FilterCondition::Empty` state r=Kerollmops a=Kerollmops
This PR is related to the issue comment https://github.com/meilisearch/MeiliSearch/issues/1338#issuecomment-989322889 which exhibits the fact that when a filter is known to be empty no results are returned which is wrong, the filter should not apply as no restriction is done on the documents set.
The filter system on the milli side has introduced an Empty state which was used in this kind of situation but I found out that it is not needed and that when we parse a filter and that it is empty we can simply return `None` as the `Filter::from_array` constructor does. So I removed it and added tests!
On the MeiliSearch side, we just need to match on a `None` and completely ignore the filter in such a case.
Co-authored-by: Clément Renault <clement@meilisearch.com>
{kind=link}
{kind=link}