376: Stop casting integer docids to string r=Kerollmops a=irevoire
When a docid is an integer, we stop casting it to a string, and thus we don't add `"` around it.
Co-authored-by: Tamo <tamo@meilisearch.com>
373: Improve error message for bad sort syntax with geosearch r=Kerollmops a=irevoire
`@Kerollmops` This should be the last PR for the geosearch and error handling, sorry for doing it in so many steps 😬
Co-authored-by: Tamo <tamo@meilisearch.com>
372: Fix Meilisearch 1714 r=Kerollmops a=ManyTheFish
The bug comes from the typo tolerance, to know how many typos are accepted we were counting bytes instead of characters in a word.
On Chinese Script characters, we were allowing 2 typos on 3 characters words.
We are now counting the number of char instead of counting bytes to assign the typo tolerance.
Related to [Meilisearch#1714](https://github.com/meilisearch/MeiliSearch/issues/1714)
Co-authored-by: many <maxime@meilisearch.com>
371: Provide a sort error handler r=Kerollmops a=irevoire
This PR simplify the error handling of asc-desc rules for Meilisearch or any other wrapper by providing directly in milli a new error type called `SortError` that can be generated from an `AscDescError` and that can be automatically converted to a `UserError`.
Basically now, wherever you are in the code as a user or in milli you can parse an `AscDesc` syntax and depending on the context, cast it either as a `SortError` or a `CriterionError` in one line with improved error messages.
Co-authored-by: Tamo <tamo@meilisearch.com>
370: Change chunk size to 4MiB to fit more the end user usage r=ManyTheFish a=ManyTheFish
We made several indexing tests using different sizes of datasets (5 datasets from 9MiB to 100MiB) on several typologies of VMs (`XS: 1GiB RAM, 1 VCPU`, `S: 2GiB RAM, 2 VCPU`, `M: 4GiB RAM, 3 VCPU`, `L: 8GiB RAM, 4 VCPU`).
The result of these tests shows that the `4MiB` chunk size seems to be the best size compared to other chunk sizes (`2Mib`, `4MiB`, `8Mib`, `16Mib`, `32Mib`, `64Mib`, `128Mib`).
below is the average time per chunk size:

<details>
<summary>Detailled data</summary>
<br>
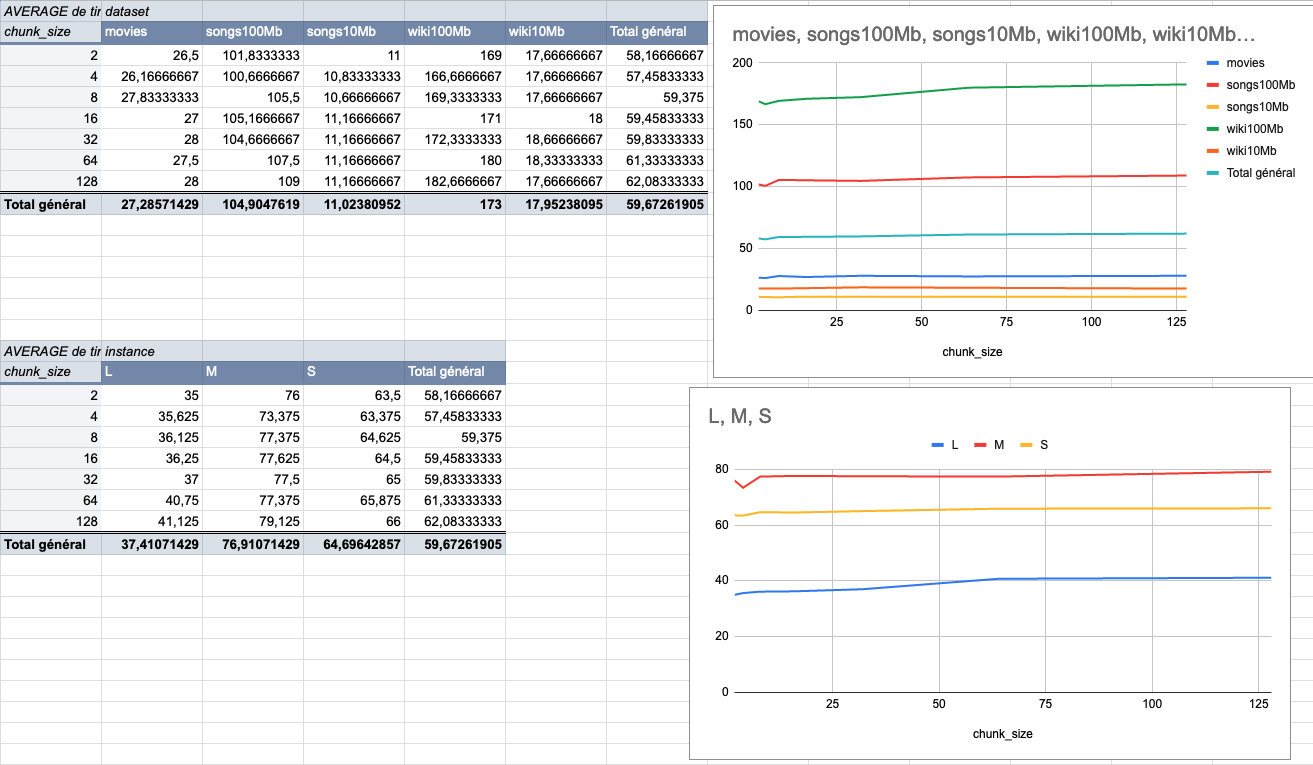
</br>
</details>
Co-authored-by: many <maxime@meilisearch.com>
369: Add test checking the bug reported in meilisearch issue 1716 r=Kerollmops a=ManyTheFish
The bug is not present in the newer milli version.
Related to [Meilisearch#1716](https://github.com/meilisearch/MeiliSearch/issues/1716)
Co-authored-by: many <maxime@meilisearch.com>
366: Geosearch error handling r=Kerollmops a=irevoire
Rewrite most of geosearch error handling and another batch of tests on the criterion parsing.
Co-authored-by: Tamo <tamo@meilisearch.com>
Co-authored-by: Irevoire <tamo@meilisearch.com>
364: Fix all the benchmarks r=Kerollmops a=irevoire
#324 broke all benchmarks.
I fixed everything and noticed that `cargo check --all` was insufficient to check the bench in multiple workspaces, so I also updated the CI to use `cargo check --workspace --all-targets`.
Co-authored-by: Tamo <tamo@meilisearch.com>
363: Fix the returned `AscDesc` error r=Kerollmops a=irevoire
With my previous PR on the geosearch I erased the change I've introduced with my pre-previous PR about the new error type when we fail to parse the `AscDesc` type.
Sorry for that, here is the fix
Co-authored-by: Tamo <tamo@meilisearch.com>
357: Add benchmarks for the geosearch r=Kerollmops a=irevoire
closes#336
Should I merge this PR in #322 and then we merge everything in `main` or should we wait for #322 to be merged and then merge this one in `main` later?
Co-authored-by: Tamo <tamo@meilisearch.com>
Co-authored-by: Irevoire <tamo@meilisearch.com>
324: Implement documents API r=Kerollmops a=MarinPostma
This pr implement the intermediary document representation for milli. The JSON, JSONL and CSV formats are replaced with the format instead, to push the serialization duty on the client side.
The `documents` module contains the interface to the new document format:
- The `DocumentsBuilder` allows the creation of a writer backed document addition, when documents are added either one by one, or as arrays of depth 1. This is made possible by the fact that the seriliazer used by the `add_documents` methods only accepts `[Object]` and `Object`. The related serialization logic is located in the `serde.rs` file.
- The `DocumentsReader` allows to to iterate over the documents created by a `DocumentsBuilder`. A call to `next_document_with_index` returns the next obkv reader in the document addition, along with a reference to the index used to map the field ids in the obkv reader to the field names
All references to json, jsonl or csv in the tests have been replaced with the `documents!` macro, works exaclty like the `serde_json::json` macro, as a convenient way to create a `DocumentsReader`.
Rewrote the search cli, to the `cli` crate, to also allow index manipulation. This only offers basic functionalities for now, but is meant to be easier to extend than http ui
blocked by #308
Co-authored-by: mpostma <postma.marin@protonmail.com>
360: Update version for the next release (v0.14.0) r=Kerollmops a=curquiza
Release containing the geosearch, cf #322
Co-authored-by: Clémentine Urquizar <clementine@meilisearch.com>
322: Geosearch r=ManyTheFish a=irevoire
This PR introduces [basic geo-search functionalities](https://github.com/meilisearch/specifications/pull/59), it makes the engine able to index, filter and, sort by geo-point. We decided to use [the rstar library](https://docs.rs/rstar) and to save the points in [an RTree](https://docs.rs/rstar/0.9.1/rstar/struct.RTree.html) that we de/serialize in the index database [by using serde](https://serde.rs/) with [bincode](https://docs.rs/bincode). This is not an efficient way to query this tree as it will consume a lot of CPU and memory when a search is made, but at least it is an easy first way to do so.
### What we will have to do on the indexing part:
- [x] Index the `_geo` fields from the documents.
- [x] Create a new module with an extractor in the `extract` module that takes the `obkv_documents` and retrieves the latitude and longitude coordinates, outputting them in a `grenad::Reader` for further process.
- [x] Call the extractor in the `extract::extract_documents_data` function and send the result to the `TypedChunk` module.
- [x] Get the `grenad::Reader` in the `typed_chunk::write_typed_chunk_into_index` function and store all the points in the `rtree`
- [x] Delete the documents from the `RTree` when deleting documents from the database. All this can be done in the `delete_documents.rs` file by getting the data structure and removing the points from it, inserting it back after the modification.
- [x] Clearing the `RTree` entirely when we clear the documents from the database, everything happens in the `clear_documents.rs` file.
- [x] save a Roaring bitmap of all documents containing the `_geo` field
### What we will have to do on the query part:
- [x] Filter the documents at a certain distance around a point, this is done by [collecting the documents from the searched point](https://docs.rs/rstar/0.9.1/rstar/struct.RTree.html#method.nearest_neighbor_iter) while they are in range.
- [x] We must introduce new `geoLowerThan` and `geoGreaterThan` variants to the `Operator` filter enum.
- [x] Implement the `negative` method on both variants where the `geoGreaterThan` variant is implemented by executing the `geoLowerThan` and removing the results found from the whole list of geo faceted documents.
- [x] Add the `_geoRadius` function in the pest parser.
- [x] Introduce a `_geo` ascending ranking function that takes a point in parameter, ~~this function must keep the iterator on the `RTree` and make it peekable~~ This was not possible for now, we had to collect the whole iterator. Only the documents that are part of the candidates must be sent too!
- [x] This ascending ranking rule will only be active if the search is set up with the `_geoPoint` parameter that indicates the center point of the ascending ranking rule.
-----------
- On Meilisearch part: We must introduce a new concept, returning the documents with a new `_geoDistance` field when it passed by the `_geo` ranking rule, this has never been done before. We could maybe just do it afterward when the documents have been retrieved from the database, computing the distance from the `_geoPoint` and all of the documents to be returned.
Co-authored-by: Irevoire <tamo@meilisearch.com>
Co-authored-by: cvermand <33010418+bidoubiwa@users.noreply.github.com>
Co-authored-by: Tamo <tamo@meilisearch.com>
359: Improve the benchmark comparison script r=irevoire a=irevoire
This modification allow us to compare more than 2 benchmarks or to only print the results of one benchmark
Co-authored-by: Irevoire <tamo@meilisearch.com>
Co-authored-by: Tamo <tamo@meilisearch.com>
{kind=link}
{kind=link}